Serverless Inference With Opportunistic Pre-Loading
——Accepted by the ACM SoCC 2024, [PDF]
Abstract
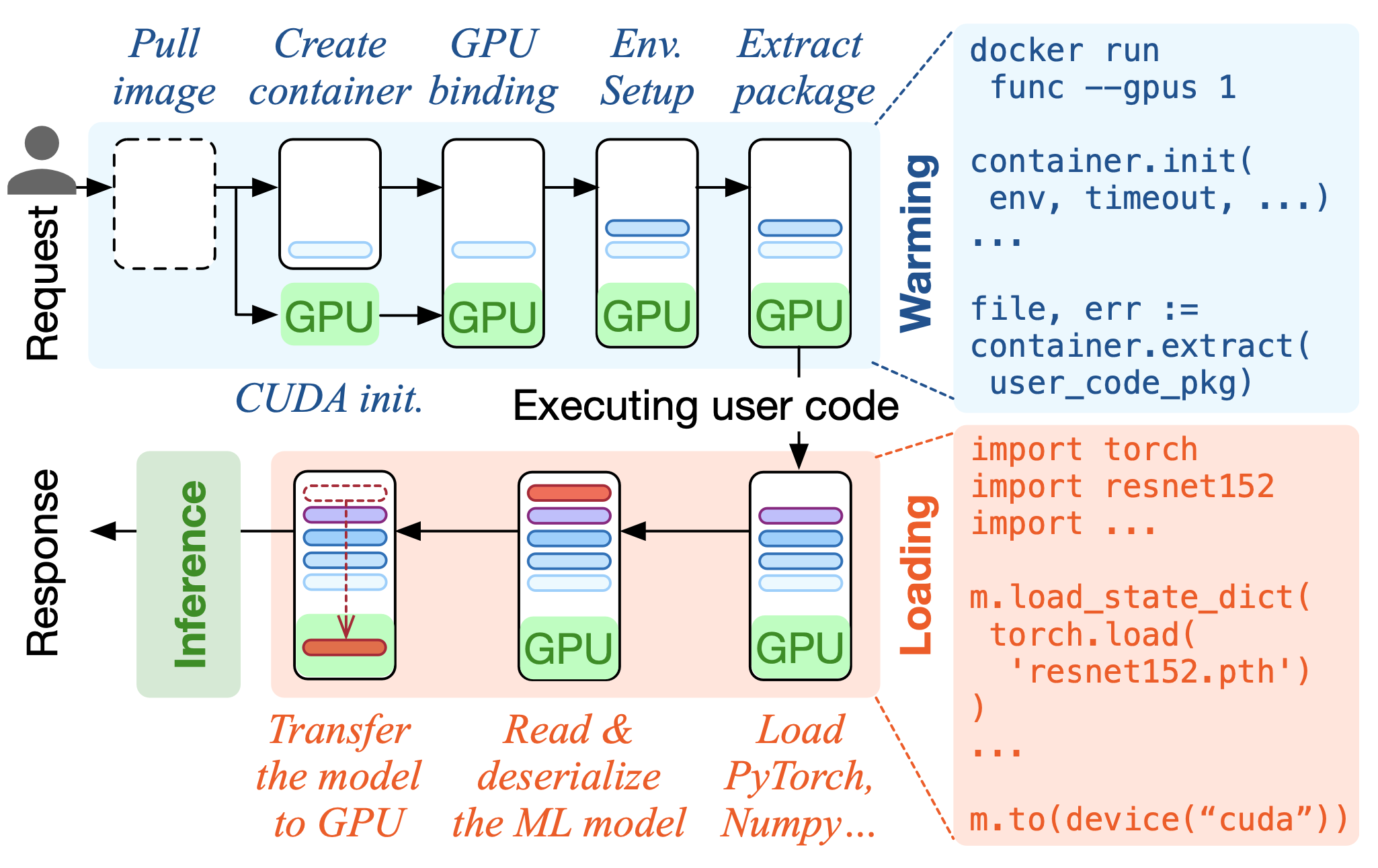
Serverless computing has rapidly prospered as a new cloud computing diagram with agile scalability, pay-as-you-go pricing, and ease-to-use features for Machine Learning (ML) inference tasks. Users package their ML code into lightweight serverless functions and execute them using containers. Unfortunately, a notorious problem, called cold-starts, hinders serverless computing from providing low-latency function executions. To mitigate cold-starts, pre-warming, which keeps containers warm predictively, has been widely accepted by academia and industry. However, pre-warming fails to eliminate the unique latency incurred by loading ML artifacts. We observed that for ML inference functions, the loading of libraries and models takes significantly more time than container warming. Consequently, pre-warming alone is not enough to mitigate the ML inference function’s cold-starts.
This paper introduces InstaInfer, an opportunistic pre-loading technique to achieve instant inference by eliminating the latency associated with loading ML artifacts, thereby achieving minimal time cost in function execution. InstaInfer fully utilizes the memory of warmed containers to pre-load the function’s libraries and model, striking a balance between maximum acceleration and resource wastage. We design InstaInfer to be transparent to providers and compatible with existing pre-warming solutions. Experiments on OpenWhisk with real-world workloads show that InstaInfer reduces up to 93\% loading latency and achieves up to 8$\times$ speedup compared to state-of-the-art pre-warming solutions.