LLM Agent Serving
Parallelizing Tool Execution and LLM Generation for Low-Latency Agent Serving, Yifan Sui, Han Zhao, Rui Ma, Zhiyuan He, Hao Wang, Kaiqiang Xu, Kai Chen, Jianxun Li, and Yuqing Yang
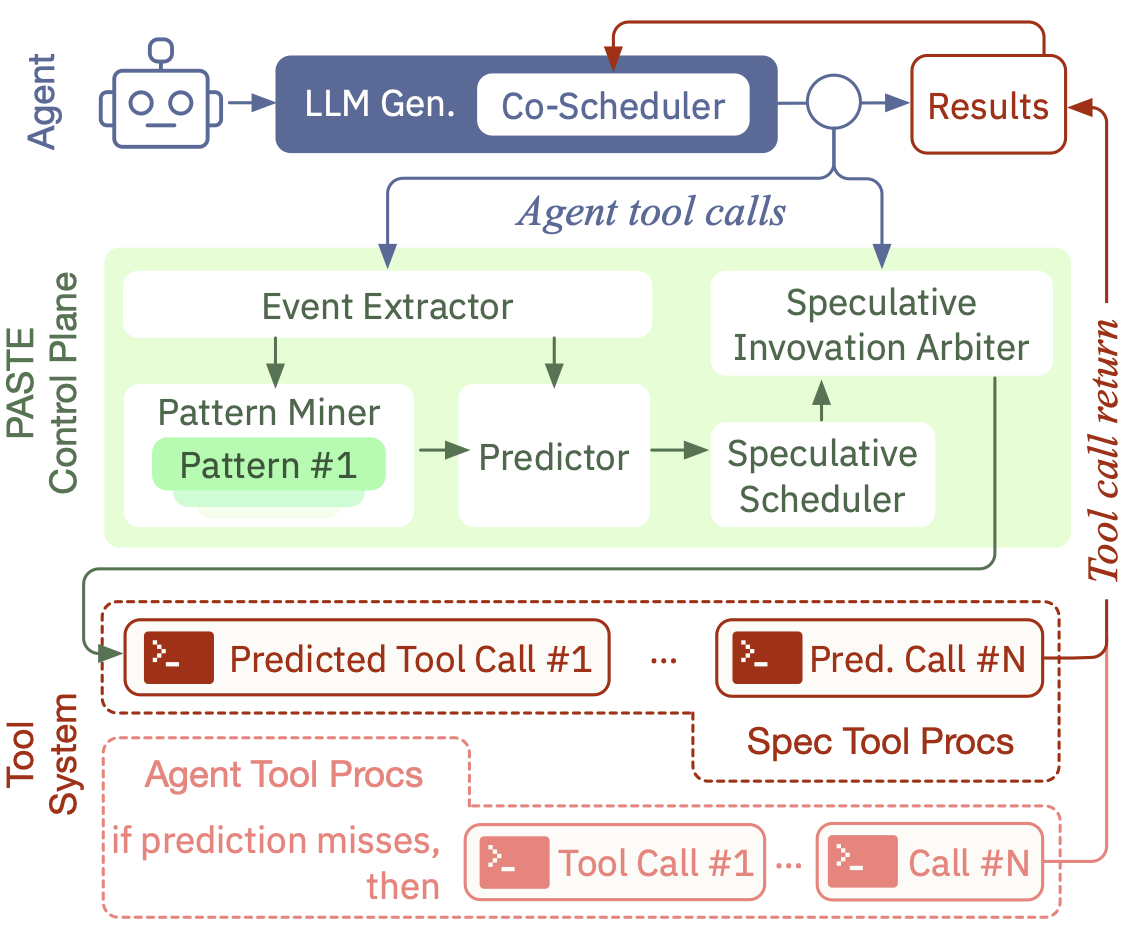
LLM-powered agents execute tasks through a sequential loop of model generation and tool execution. Today’s serving systems serialize this loop, leaving tool latency exposed on the task critical path. This paper presents PASTE, a tool-aware agent-serving system that predicts concrete future tool invocations from recurring agent patterns and executes them speculatively while the LLM is still generating. PASTE isolates speculative results until confirmed by the LLM and jointly schedules tool execution and returning LLM sessions to avoid shifting bottlenecks to the GPU. Across deep research, coding, and scientific-agent workloads, PASTE reduces average task completion time by 43.5% and lowers observed tool latency by 1.8x.